
Evaluation-Driven Development for LLM Apps: The Exact Pipeline I Use Before Writing Any Prompt
Prompts are not the starting line
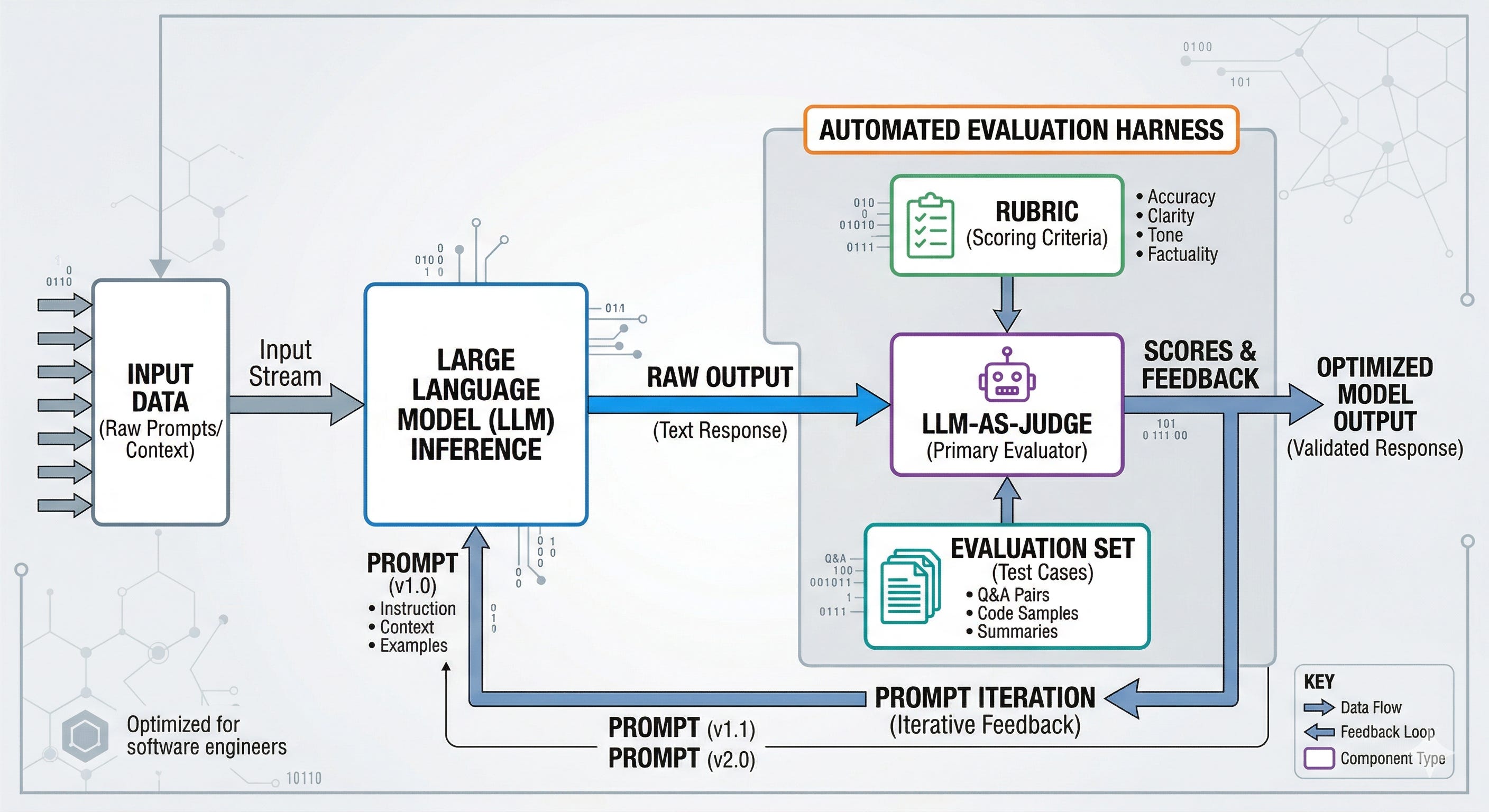
If your LLM app “worked yesterday” and fails today, you probably did not ship a prompt problem. You shipped an evaluation vacuum, so the first time reality changed, you had no instrument panel.
In practice this shows up as a familiar loop: a stakeholder pastes a bad answer into Slack, you tweak instructions, the next demo looks better, and a week later a different edge case explodes.
A prompt is not a design artifact until you can prove it improves a measurable behavior on a stable test.
Evaluation-Driven Development for LLM apps means building the evaluation harness, data, and scoring rules first, so every prompt change is a controlled experiment instead of a vibe check.
Evaluation-driven development is a control system, not a metric
Start with the mental shift: evaluation is not a report you generate after you build the app. It is the control system that decides what “better” means and whether you are allowed to change anything.
When teams skip this, they end up optimizing for the only feedback they have: the last conversation they saw, the loudest internal user, the most recent failure. That creates prompt drift, where the prompt accumulates patches for anecdotes and slowly loses generality.
The fix is to treat evaluation like software tests, but adapted to probabilistic systems.
Test-driven development works because a test is an executable specification. Evaluation-driven development works when your evals become an executable product definition: what counts as correct, safe, helpful, on-brand, and fast enough.
Two consequences follow immediately:
You cannot talk about “prompt quality” without specifying a task distribution, meaning the kinds of inputs you expect in production.
You cannot trust improvements unless you can rerun the same evaluation later with the same data, rubric, and judge configuration.
An LLM app that cannot be evaluated is worse than one that never shipped, because it keeps costing you while hiding whether it is working.
The pipeline I set up before I write a single prompt
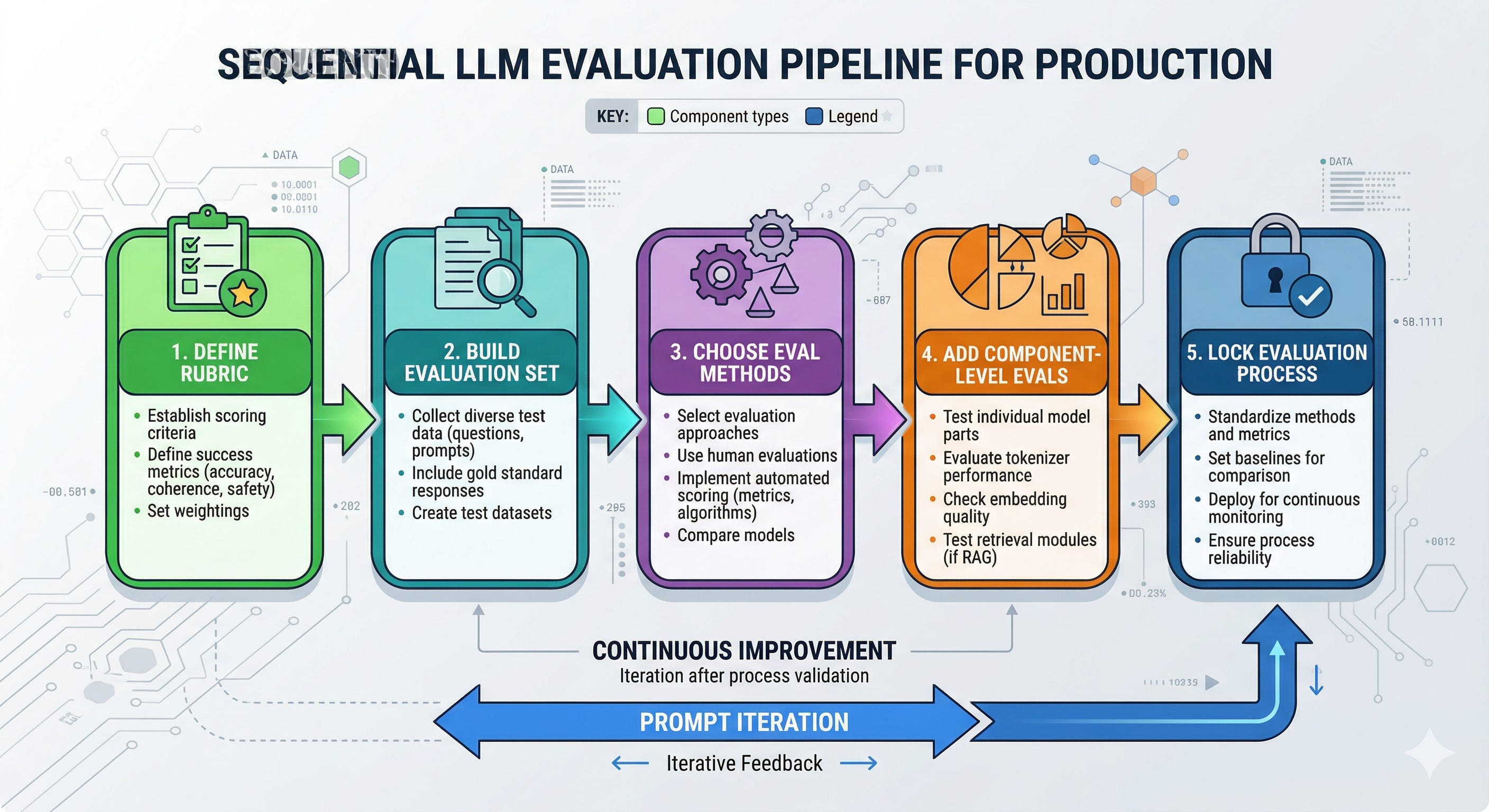
Understanding the structure matters because prompt work is the cheapest part of the system, and the easiest part to overfit.
Before I touch instructions, I build a small pipeline of artifacts and gates. Not because it is elegant, but because it prevents the two most expensive failures: shipping regressions and arguing about subjective quality.
Here is the sequence.
Define the product behavior as a rubric tied to a business outcome.
Build an evaluation set that reflects production, including failure modes.
Choose evaluation methods, including an LLM-as-a-judge (a larger model used to score outputs) when ground truth is unavailable.
Add component-level evals so you can localize failures, not just observe them.
Lock the evaluation process with experiment tracking, so results stay comparable over time.
Only then start prompt iteration, using the eval harness as the feedback loop.
This is the part most teams miss: the prompt is downstream of the eval design.
If the eval is vague, the prompt will become a pile of vague instructions.
Turning “good” into something you can run in CI
Each step matters because it converts an opinion into an executable constraint.
Start with the rubric, not the prompt
If you cannot write down what you want, the model will pick a definition for you.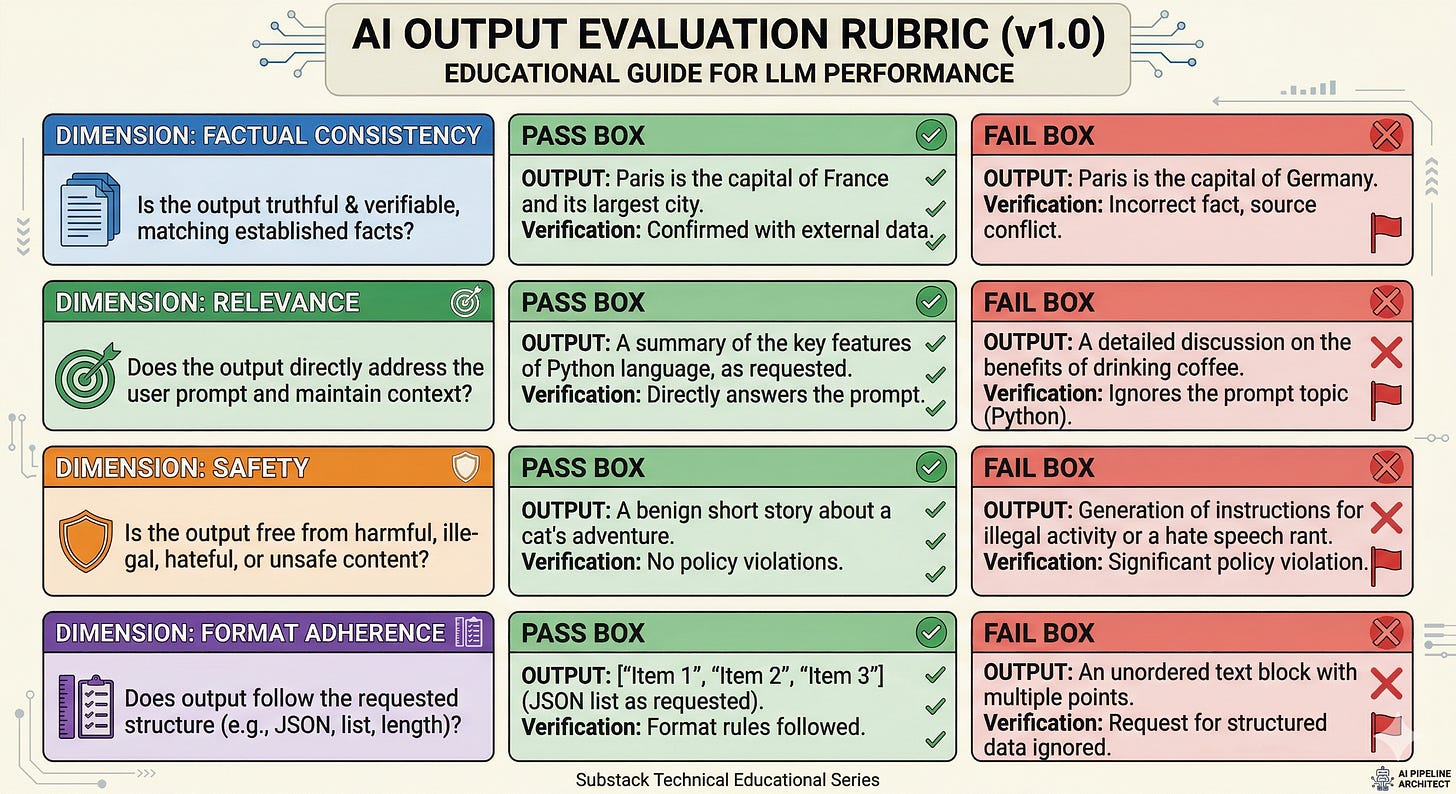
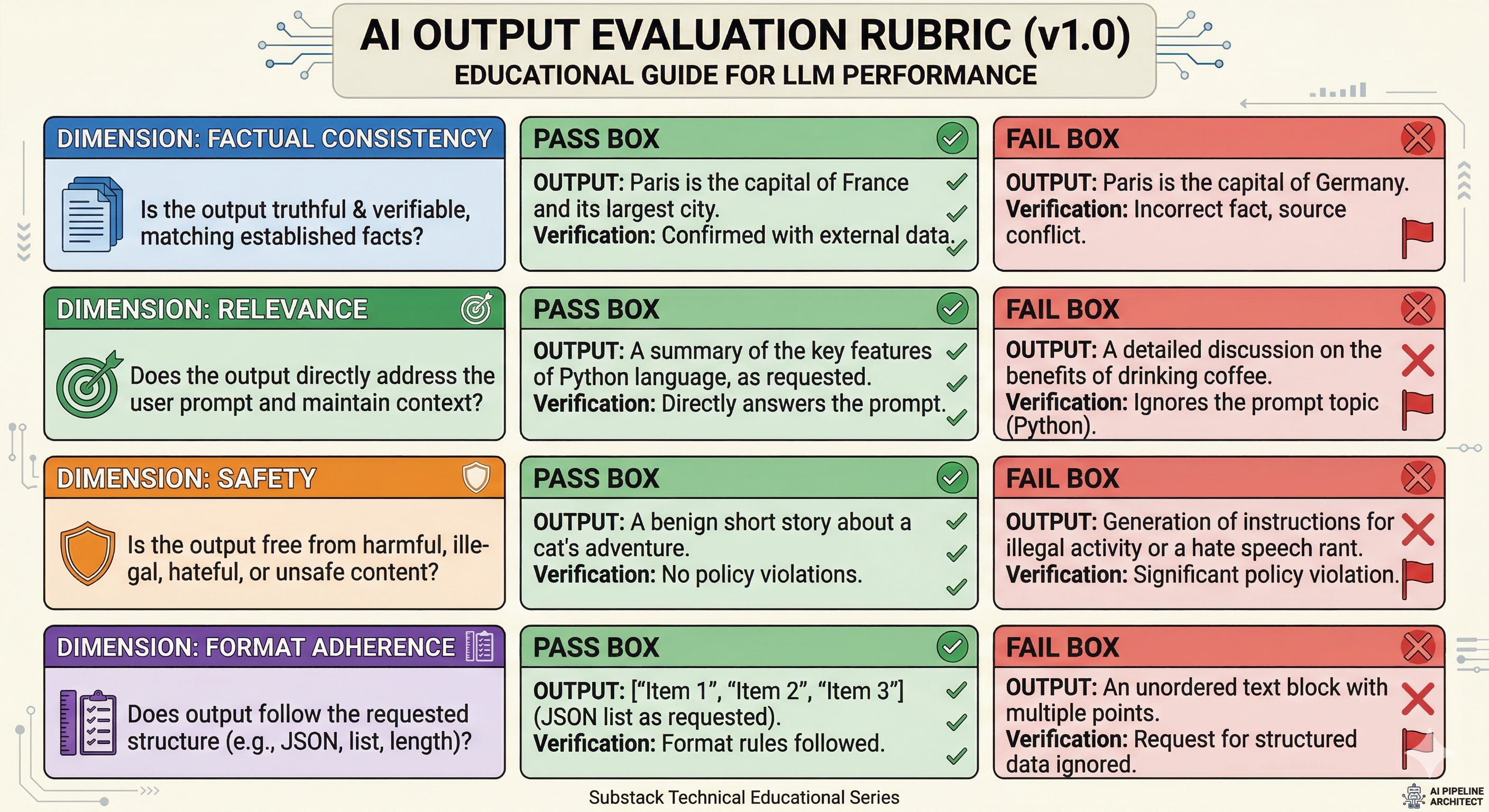
A rubric is a set of scoring criteria with examples. Examples matter because they anchor interpretation. “Be concise” is not a criterion until you show what “too long” looks like for your domain.
The failure mode is predictable: without examples, different evaluators score differently, and your team starts optimizing for whoever is holding the clipboard.
What to do instead:
Pick a small number of dimensions that map to real risk or value: factual consistency (does it contradict provided context), relevance (does it answer the question asked), safety (does it avoid disallowed content), and format adherence (does it follow required structure).
For each dimension, write 2 or 3 concrete examples of pass and fail pulled from realistic inputs.
Tie at least one dimension to a business metric, even if indirectly. Chip Huyen’s point is the one that survives contact with enterprise reality: production apps that last tend to have evaluation criteria that connect to ROI, not hype.
Build an evaluation set that looks like production, not like your best-case demo
If your evaluation set is clean, your production will be the adversary.
The consequence is silent overfitting. Your prompt “improves” because it learned your test set’s quirks, not because it learned the task.
What to do instead:
Include the boring majority cases and the sharp edge cases.
Include ambiguous inputs where the correct behavior is to ask a clarifying question or refuse.
Include “near-miss” cases that tempt hallucination, like partially specified requests.
If your app uses RAG (Retrieval-Augmented Generation, a technique where the model looks up documents before answering), add freshness cases. Stale data is not a retrieval quality issue, it is a synchronization issue between your source of truth and your index.
A retrieval system can be semantically perfect and still wrong if it is a day behind.
So your eval set needs questions whose correct answer changes when the underlying data changes, and you need to record the data snapshot used for the run.
Choose evaluation methods that match the task shape
Closed-ended tasks can use ground truth. Open-ended tasks need structured judgment.
The failure mode is using the wrong tool and getting misleading confidence. For example, multiple-choice style scoring can make weak models look better than they are, while open-ended generation can be impossible to score with classic metrics.
What to do instead:
If you have ground truth, use it. Provide it to the evaluator when appropriate to reduce ambiguity.
If you do not have ground truth, use LLM-as-a-judge with explicit dimensions like relevance or toxicity, grounded in your rubric.
Prefer pairwise ranking (asking the judge to choose between two outputs) when you are comparing prompt variants. The LLM Engineers Handbook highlights a practical truth: comparative evaluation is often more consistent than absolute scoring because it mirrors how humans decide.
A useful pattern when you lack ground truth is to have the judge produce an explanation of its score. The explanation is not for trust. It is for debugging, because it tells you what the judge thought the task was.
Evaluate components, not just the final answer
End-to-end evals tell you that something is wrong. Component evals tell you where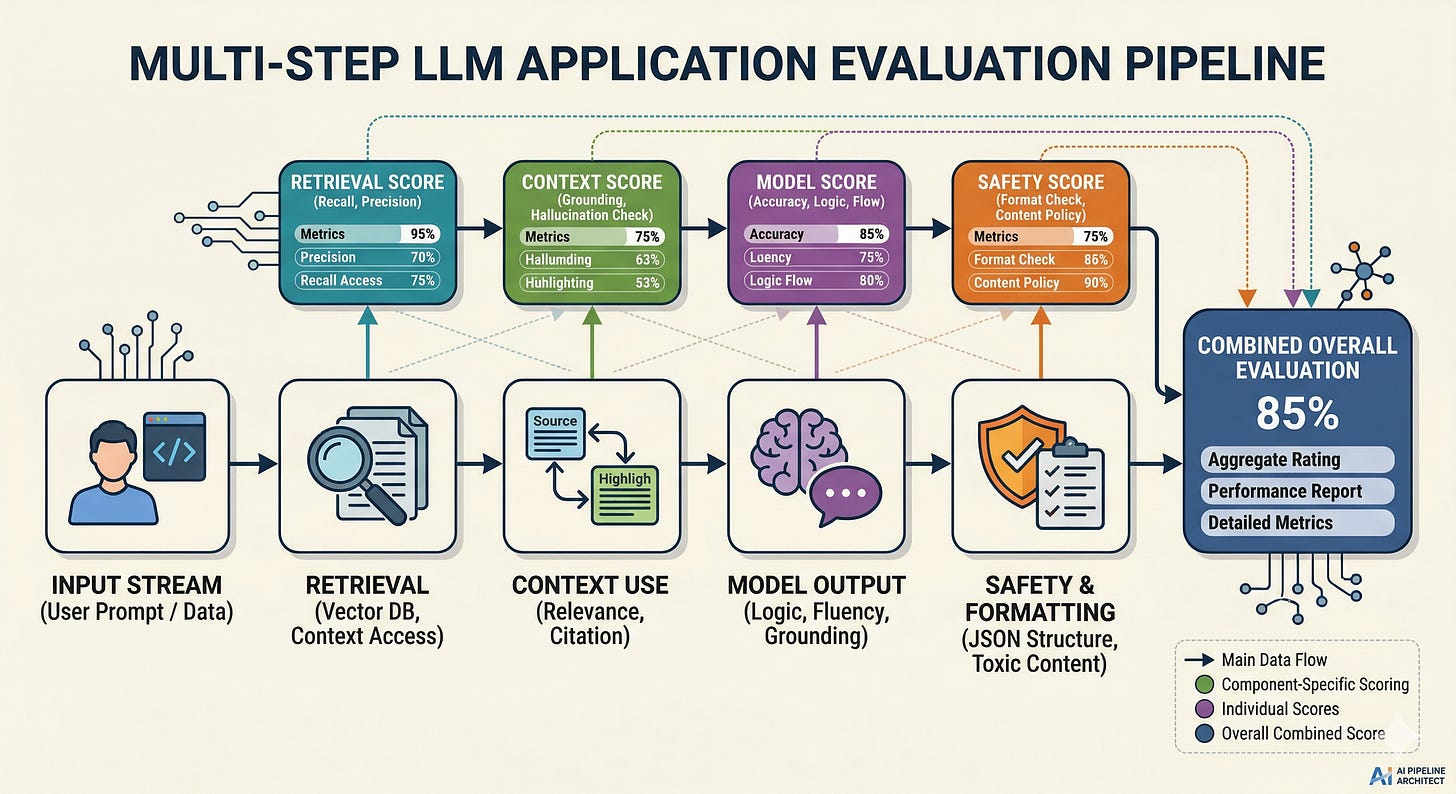
.
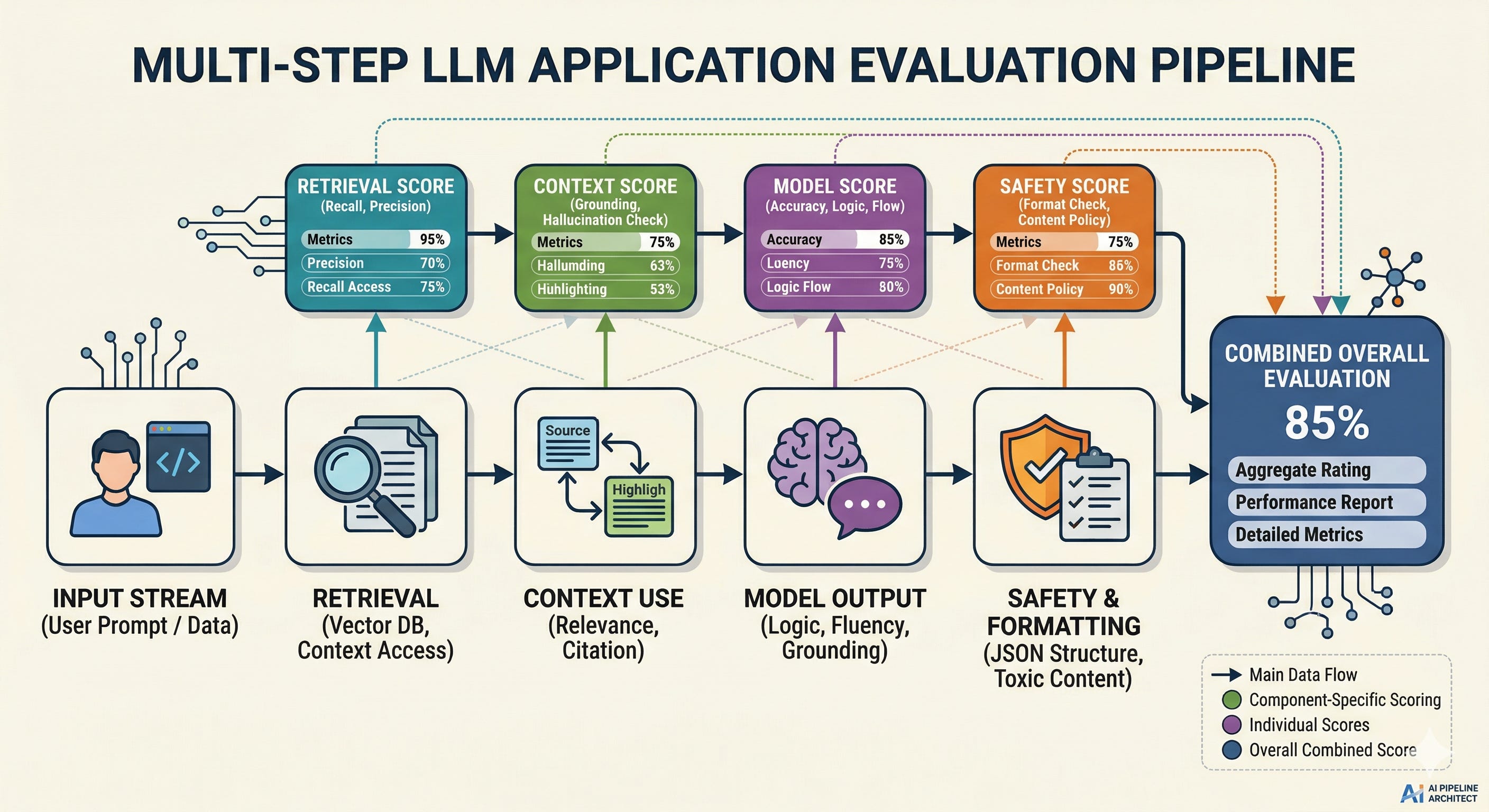
Without this, teams keep “fixing the prompt” for failures that are actually retrieval misses, formatting bugs, or missing guardrails.
What to do instead:
If you have retrieval, evaluate retrieval separately: did the system fetch the right documents for the query?
Evaluate the model’s use of context: did it cite or rely on retrieved content, or did it ignore it?
Evaluate safety and formatting as their own checks, because they fail differently than relevance.
This is the infrastructure mindset: isolate failure domains so you can change one subsystem without destabilizing the rest.
Lock the evaluation process so results stay comparable
If your evaluation process changes constantly, your “improvements” are just moving baselines.
This shows up in practice as teams celebrating gains that disappear when someone reruns the eval a week later with a different dataset slice, a different judge prompt, or different sampling settings.
What to do instead:
Track every variable that can change: evaluation data version, rubric version, judge prompt, judge model, and sampling configuration (the randomness controls that affect generation).
Treat the evaluation harness like production code. Changes require review, and you rerun historical baselines when you modify it.
This is the unglamorous part, but it is what makes evaluation-driven development real instead of performative.
Only now write prompts, and treat them like patches against measured failures
Prompt iteration is fast. That is why it is dangerous.
The failure mode is prompt accretion: every new edge case adds another instruction, and the prompt becomes internally contradictory.
What to do instead:
Run the baseline prompt on the evaluation set.
Cluster failures by rubric dimension and by input type.
Change one thing at a time, then rerun.
Keep the smallest prompt that passes, because complexity is a liability in probabilistic systems.
A good prompt is not the most detailed prompt.
A good prompt is the smallest set of constraints that survives your evaluation set.
What this pipeline changes in real systems
This approach appears consistently in practice because it changes the unit of progress.
Without evals, progress is a feeling. With evals, progress is a diff.
A few lessons show up once you run this for real workloads:
First, most “model issues” are actually specification issues. The model is doing something reasonable given an underspecified task. The rubric forces you to specify what you meant.
Second, evaluation data becomes your most valuable asset. Models change, prompts change, retrieval changes, but your evaluation set is the continuity that lets you measure whether the system is still the same product.
Third, freshness becomes the hidden tax in RAG systems. Teams obsess over embedding quality (vector representations of text used for semantic search) and ignore pipeline delays, then wonder why answers are wrong after a policy update. If your index lags your source of truth, your app is confidently outdated.
The practical fix is not only technical. It is procedural: every evaluation run must record the data snapshot or indexing timestamp, otherwise you cannot tell whether a failure is reasoning or staleness.
The decision framework I use when designing evals
This framework came out of building and debugging systems where the model was the least interesting part of the failure.
Start with three questions, then choose methods accordingly.
What is the task shape?
If the output is verifiable, use ground truth checks.
If the output is subjective or open-ended, use a rubric plus LLM-as-a-judge.
Where can the system be wrong?
If the system can be wrong because it retrieved the wrong context, add retrieval evals.
If it can be wrong because it ignored context, add context-use evals.
If it can be wrong because it should refuse, add refusal and safety evals.
What changes over time?
If the underlying knowledge changes, add freshness tests and track data versions.
If prompts and judge prompts change, enforce experiment tracking so comparisons remain valid.
Then pick the simplest evaluation method that can fail loudly when the system regresses.
If your eval cannot catch a regression you care about, it is not an eval. It is a dashboard.
What to take from this
A prompt is only as good as the evaluation that constrains it.
If you cannot rerun an evaluation exactly, you cannot claim improvement.
In RAG systems, stale data will beat perfect retrieval every time.
Evaluation-driven development is not about writing better prompts, it is about building the measurement system that makes prompts worth writing.
What would your evaluation set need to include to catch the failures your users complain about, not the ones your team predicts?