
RAG Evaluation in CI/CD: Versioning Prompts, Data, and Retrieval Config So Your Scores Mean Something
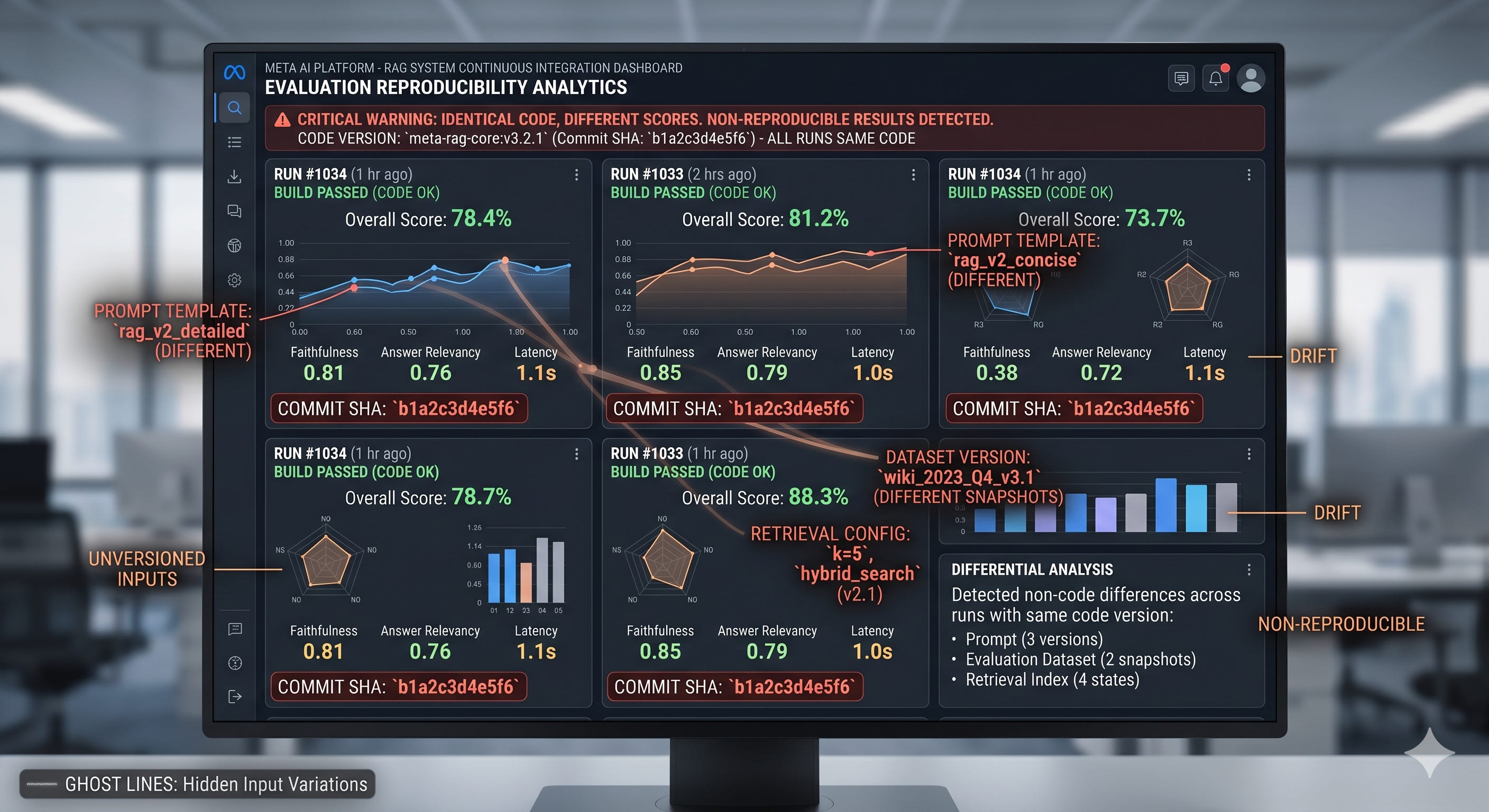
The CI score went up, and nobody could explain why
If your RAG eval score jumps after a “small refactor,” you probably did not improve the system. You probably changed what the test is measuring.
A team merges a PR that “only” tweaks chunking and a prompt template. CI reports faithfulness up ~0.12, answer relevancy down ~0.05, and latency flat. The next day, someone reruns the same job and the numbers move again, even though the code did not.
RAG evaluation in CI/CD only works when prompts, data snapshots, and retrieval configuration are versioned as first-class artifacts so each score is tied to a reproducible system state.
RAG evaluation is a measurement system, not a leaderboard
Start with the uncomfortable truth: most RAG (Retrieval-Augmented Generation, a pattern where the model retrieves documents before answering) “evaluation” pipelines are not evaluations. They are comparisons between two moving targets.
What is actually happening in CI is that you are measuring an end-to-end behavior that depends on at least four coupled subsystems:
The prompt and formatting that shape what the model tries to do
The retrieval stack that decides what context the model sees
The corpus and indexing pipeline that decide what can be retrieved
The judge or metric implementation that decides what “good” means
The consequence is predictable. You cannot interpret deltas.
A +0.10 faithfulness change can mean the model is more grounded. It can also mean you shortened answers, changed the judge prompt, retrieved fewer documents, or accidentally evaluated against a different snapshot of the corpus.
If you want scores that mean something, treat evaluation like metrology. Fix the instrument, version the inputs, and only then compare outputs.
The most common failure mode in real systems is not low retrieval quality. It is silent drift between what you think you evaluated and what the pipeline actually ran.
The three version lines that decide whether your numbers are real
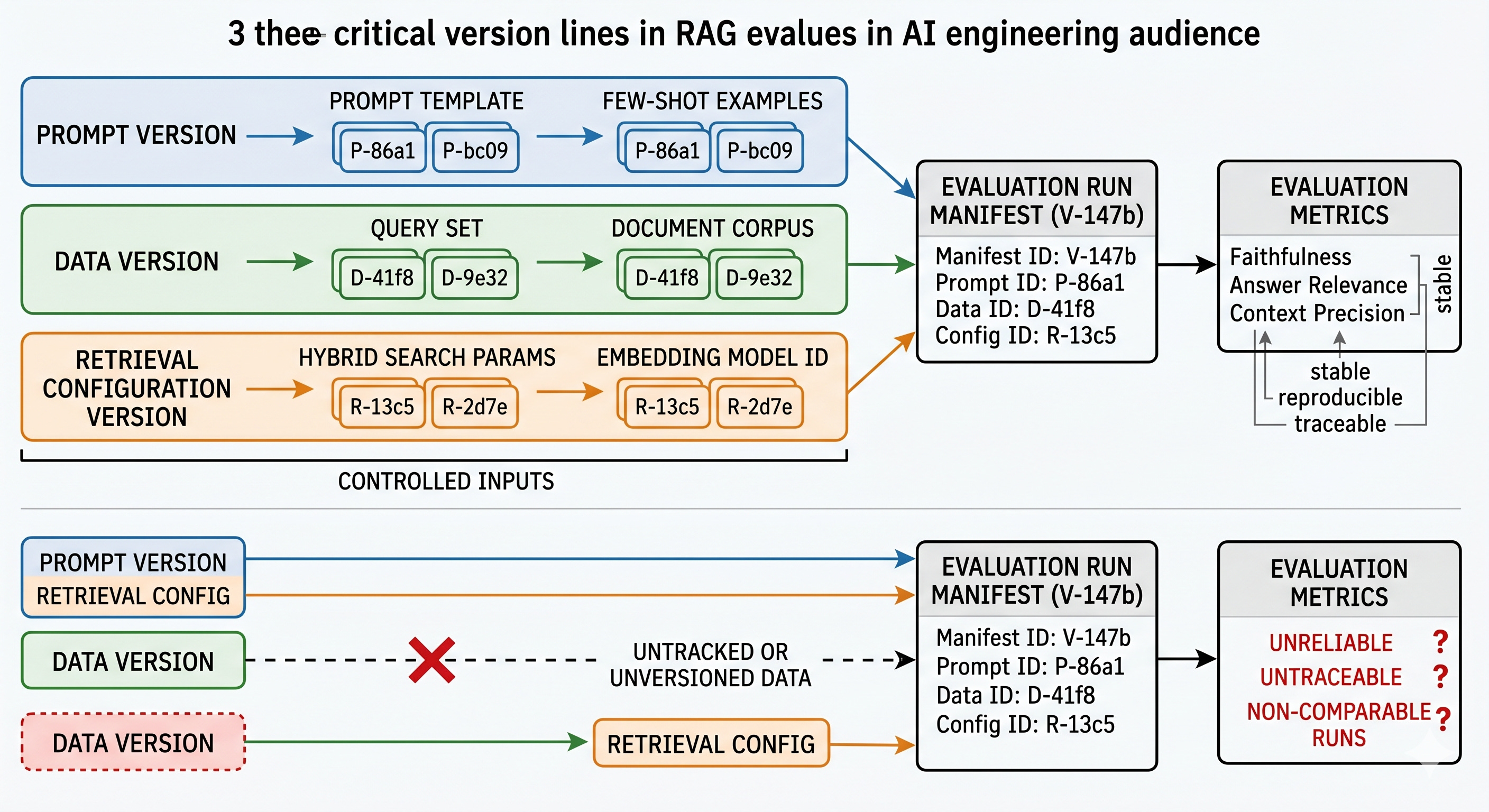
Understanding the structure matters because RAG quality is an emergent property of a pipeline, and pipelines only become comparable when their degrees of freedom are pinned down.
Think in terms of three version lines that must be present in every CI evaluation record.
Prompt version line
This is not just “the prompt text.” It is the full prompt contract: system message, developer instructions, tool schemas if you use tools, output format constraints, and any few-shot examples.
Why it breaks: prompt edits are often “non-functional” changes that still shift behavior. Even whitespace and formatting can change how the model segments instructions. More importantly, evaluation tools do not share judge prompts. Chip Huyen’s point is the one that bites teams: different tools can use very different default rubrics for the same metric, so scores are not comparable across tools or even across versions of the same tool.
What to do instead: version prompts like code, but record them like data. Store the rendered prompt template and the variable bindings used for each test case. If you use an AI judge (an LLM used to score outputs), pin its configuration too, including temperature set to 0 for determinism, and record the judge prompt text.
Data version line
For RAG, “data” is not a single thing. It is the corpus snapshot, the chunked representation, and the index built from it.
Why it breaks: freshness and synchronization gaps dominate. Your CI job might run against yesterday’s index because the embedding job lags, or because the index build is asynchronous. You think you tested “the new docs,” but retrieval is still serving the old embedding space.
What to do instead: treat the corpus snapshot and the index as immutable artifacts. Record a content hash for the raw documents, a hash for the chunked output, and an identifier for the built index. If any of those are “latest,” your evaluation is not reproducible.
Retrieval configuration version line
Retrieval config is the hidden prompt. It decides what evidence the model is allowed to see.
This includes chunk size and overlap, embedding model choice, top-k, any re-ranking (a second-stage model that reorders retrieved results), filters, and the context assembly policy (how you pack retrieved chunks into the model input).
Why it breaks: retrieval changes often look like “infra tweaks,” so they slip into PRs without being treated as behavior changes. But context precision and context recall, as described in Ragas, are directly shaped by these knobs. Change top-k from 5 to 10 and you might increase recall while decreasing precision, which can lower faithfulness if the model starts blending irrelevant context.
What to do instead: define a retrieval config object and version it. Store it alongside the eval run, not in a wiki. If retrieval config is not serialized and attached to the score, the score is an anecdote.
Evaluation without these three version lines is not a signal. It is a story you tell yourself.
What a CI/CD RAG eval pipeline looks like when it is actually controlled
Applying this in CI/CD is mostly about making the pipeline produce a single, queryable “evaluation run artifact” that captures the entire state.
Start by separating two ideas that get conflated:
CI is for catching regressions on controlled fixtures.
Production monitoring is for catching drift on live traffic.
Ragas is explicitly built around metrics-driven development, meaning you track metrics over time and use them to guide iteration. That only works if “over time” means “comparable.”
Here is a practical breakdown of how to implement it without turning CI into a research project.
Define an evaluation manifest that is the unit of reproducibility
Why it matters: you need one object that answers “what exactly ran?” without reading logs.
The manifest should include:
Git commit SHA for the application code
Prompt template identifier and prompt content hash
Retrieval config identifier and serialized config
Corpus snapshot identifier and index identifier
Model identifier for generation, plus decoding settings
Judge identifier and judge settings if you use LLM-based metrics
If you cannot reconstruct the run from the manifest, the manifest is incomplete.
Make the dataset a pinned artifact, not a folder in the repo
Why it matters: evaluation datasets drift quietly when they live as “just JSON” in the codebase, or when they are regenerated without lineage.
Ragas can synthetically generate diverse test datasets using an evolutionary approach inspired by Evol-Instruct, which is useful because manual dataset creation does not scale. The trap is regenerating synthetic sets and calling it “the same benchmark.”
Treat each dataset build as immutable. Store:
The dataset content hash
The generator configuration and seed if applicable
The source document snapshot it was generated from
If you want to refresh the dataset, that is a new dataset version, not an overwrite.
Split evaluation into fast gates and slow audits
Why it matters: evaluation can add cost and latency, and teams start skipping it. Chip Huyen calls that a risky bet, and in practice it becomes a reliability issue, not a cost issue.
A workable pattern:
Fast gate in PR CI: small fixed dataset, deterministic settings, regression thresholds
Slow audit on main or nightly: larger dataset, more metrics, deeper slicing
The key is that both produce the same manifest format so you can compare runs.
Pin judge behavior or your metric is a moving target
Why it matters: AI judges are also AI applications. They can change when the underlying model changes, when the prompt changes, or when the tool updates defaults.
If you use Ragas metrics like faithfulness and answer relevancy, record:
The exact metric implementation version
The judge model identifier
Temperature 0
Any rubric prompt text
Different tools can define “faithfulness” differently, as the handbook excerpt shows. If you switch tools or upgrade versions, you are starting a new metric series.
Add freshness checks as first-class CI assertions
Why it matters: a RAG system can look “good” in CI while serving stale context in production, or vice versa. Freshness is a pipeline property, not a retrieval property.
Add explicit checks:
Index build timestamp must be >= corpus snapshot timestamp
Corpus snapshot timestamp must be >= dataset snapshot timestamp if the dataset depends on it
Retrieval must report which index identifier it queried
If any of these are unknown, fail the evaluation as “not comparable,” not as “bad quality.”
Store per-example traces, not just aggregate scores
Why it matters: aggregate metrics hide failure modes. A small change can improve the mean while breaking a critical slice.
For each test case, store:
Retrieved document identifiers and ranks
The assembled context sent to the model
The model output
The metric sub-scores and judge rationales if available
This is where RAG evaluation becomes engineering. You debug retrieval and prompting with evidence, not with averages.
The failure modes that keep showing up in practice
In most real-world cases, teams do not fail at “choosing metrics.” They fail at controlling the evaluation surface area.
The prompt drift trap
Someone edits the system prompt to “be more concise.” Faithfulness improves because there are fewer claims to verify. Ragas faithfulness works by breaking answers into claims and checking whether each claim is supported by context. Fewer claims can inflate the ratio.
The fix is not “never change prompts.” The fix is to interpret prompt edits as behavior changes and require a new prompt version line. Then slice metrics by answer length and claim count so you can see when you improved grounding versus when you just spoke less.
The stale index trap
Docs update, but embeddings and indexing lag. CI runs against a cached index. Production runs against a different one. Your evaluation becomes a parallel universe.
The fix is to make index builds explicit artifacts with identifiers, and to block evaluation if the index is not built from the declared corpus snapshot.
The retrieval config shadow change
A developer changes top-k, adds a filter, or modifies chunk overlap to reduce latency. Context recall drops, but answer relevancy stays flat because the model hallucinates plausible answers. Your “quality” looks stable until a user asks a question that requires the missing context.
The fix is to treat retrieval config as part of the API of your RAG system. Version it, review it, and test it with cases designed to fail when recall drops.
The judge drift trap
You upgrade an evaluation library and the default judge prompt changes. Scores shift. Nobody can explain it, so the team stops trusting evaluation.
The fix is to pin judge prompts and versions. If you must change them, fork the metric series. Do not pretend the time series is continuous.
A metric that cannot survive a rerun is not a metric. It is a vibe.
A decision framework for making RAG eval changes without breaking comparability
This framework comes from the same place most infra frameworks come from: too many “why did the score change?” incidents and not enough time to replay history.
Treat every change as belonging to one of three buckets, and handle it accordingly.
Instrument changes
These change how you measure, not what you built. Examples: judge prompt edits, metric implementation upgrades, switching evaluation tools.
Rule: instrument changes start a new metric series. Keep the old series for historical comparison, but do not mix.
Input changes
These change what the system can know. Examples: corpus snapshot updates, chunking changes, embedding model changes, index rebuilds.
Rule: input changes require a new dataset-to-corpus compatibility check and freshness assertions. If your dataset was generated from old docs, expect recall metrics to lie.
Behavior changes
These change how the system uses inputs. Examples: prompt edits, retrieval top-k changes, re-ranking changes, context assembly changes.
Rule: behavior changes must be evaluated against a fixed dataset and fixed instrument. If you change behavior and instrument together, you will not know what caused the delta.
When you follow this, CI becomes a place where deltas mean something. You can say “retrieval config v3 improved context precision by ~0.08 on dataset v12 under judge v5,” and that sentence is operationally true.
What to take from this
A RAG score without prompt, data, and retrieval version lines is not evidence.
Freshness and synchronization gaps are the fastest way to make evaluation disagree with production.
If you cannot rerun an evaluation and get the same result, you do not have CI. You have theater.
RAG evaluation in CI/CD is not about getting higher scores, it is about making scores attributable to a specific, reproducible system state.
Which of your current RAG eval numbers would still be defensible if you had to reproduce them exactly 30 days from now?