
The AI Engineering Mindset: What It Really Means to Build AI Products
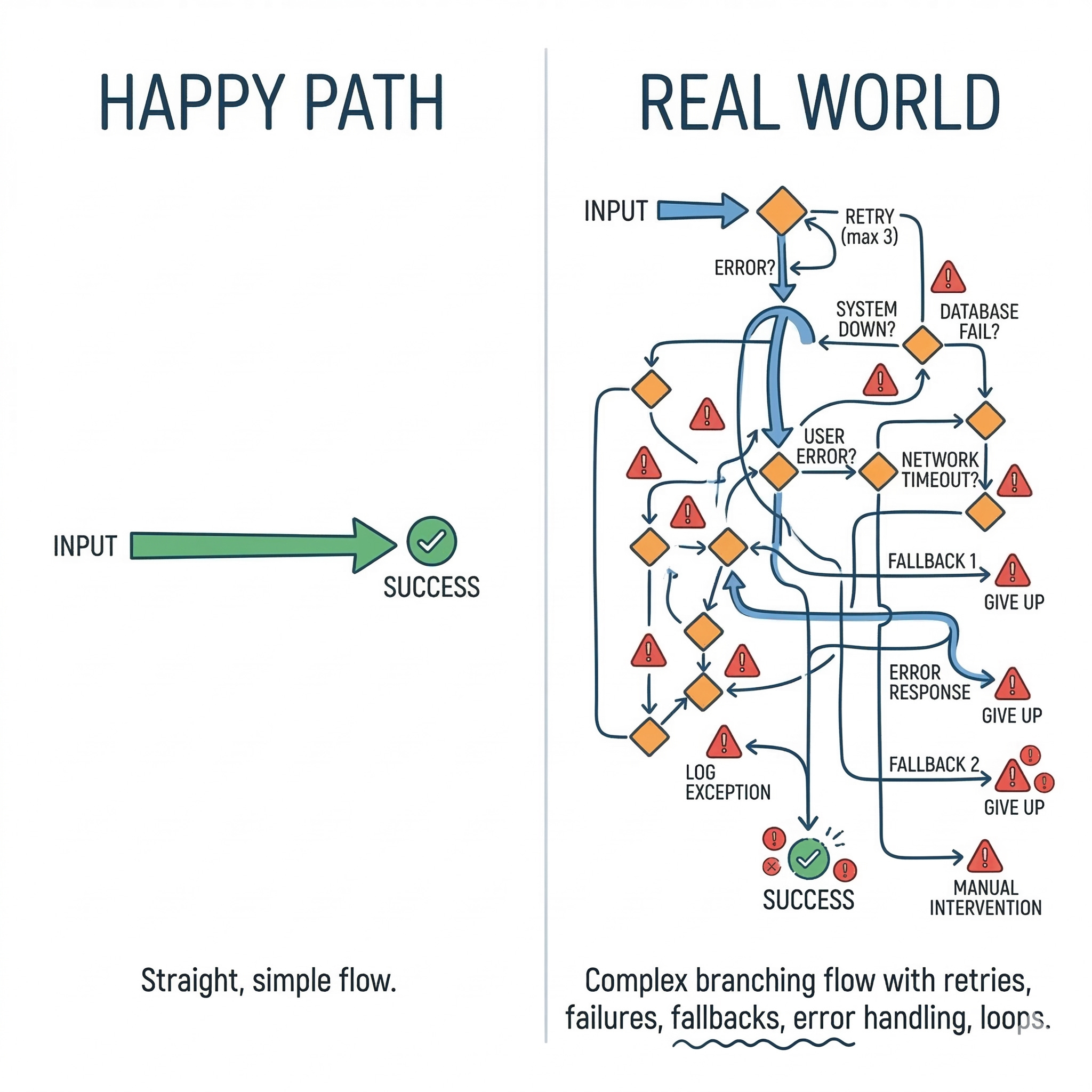
The demo is not the product.
A support ticket comes in at 2 a.m. The agent told a customer to reset the wrong account, because it pulled context from a stale document and then confidently filled in the gaps. In your notebook, the same prompt looked perfect.
The demo is not the product.
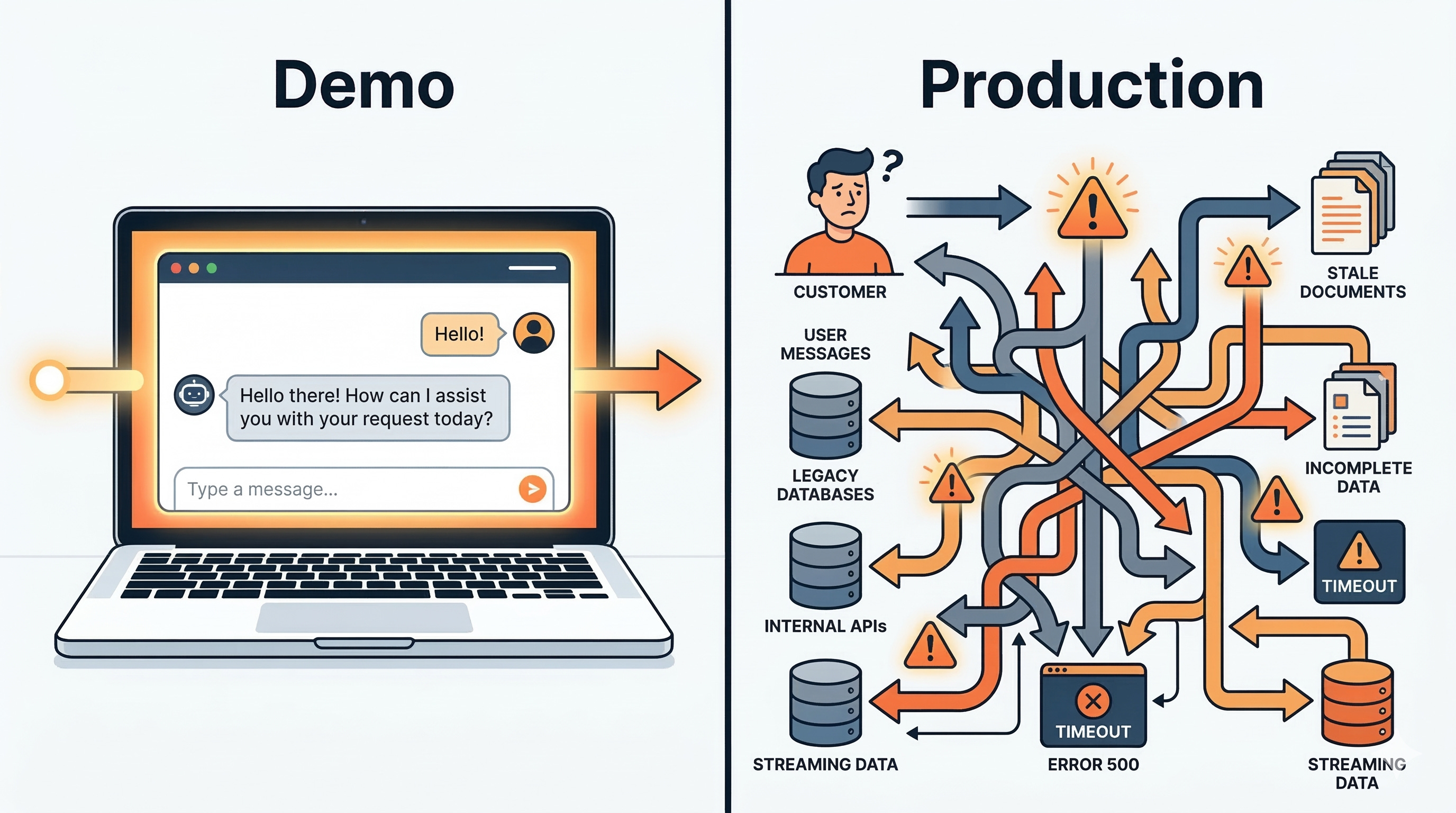
Building AI products means engineering a system where probabilistic model behavior is constrained by deterministic software, data, and feedback loops.
The mindset shift: from model output to system behavior
This is not about getting the model to say the right thing once.
It is about getting the system to behave acceptably across messy inputs, partial context, traffic spikes, and changing requirements. That is the core mindset shift.
In classic software, you can often reason from code to outcome. In AI products, you reason from system design to outcome distributions.

The model is a component that produces a range of possible outputs. Your job is to shape that range and detect when it drifts.
This is why AI engineering looks like ML engineering in some places but feels closer to distributed systems in others. You still care about latency, cost, and reliability. But you also care about evaluation, data quality, and failure modes that look like “it sounded right” instead of “it crashed.”
A practical way to define the AI engineering mindset is this:
Treat the model as an unreliable collaborator.
Treat the rest of the system as the contract.
Build the contract so you can measure it, enforce it, and improve it.
Chip Huyen frames this shift well in AI Engineering: with foundation models, you spend less time training and more time adapting and evaluating. That is exactly what product work feels like. You are not shipping a model. You are shipping an adaptation loop.
What you are really building when you “build an AI product”
This section matters because it clarifies what the unit of work actually is.
An AI product is an orchestration layer around a model. It turns user intent and system state into constrained model inputs and turns model outputs into safe actions.
That orchestration layer usually includes:
Input shaping: cleaning, normalization, language detection, PII handling, and intent classification.
Context construction: retrieval, tool results, user profile, conversation state, and policy snippets.
Generation: model selection, prompt templates, decoding settings, and structured output constraints.
Post-processing: parsing, validation, redaction, citation formatting, and confidence signals.
Action execution: calling downstream APIs, writing to databases, sending emails, or updating tickets.
Observability and evaluation: traces, logs, offline test sets, online metrics, and human review queues.
Feedback loop: capturing outcomes and using them to improve retrieval, prompts, routing, and sometimes fine-tuning.
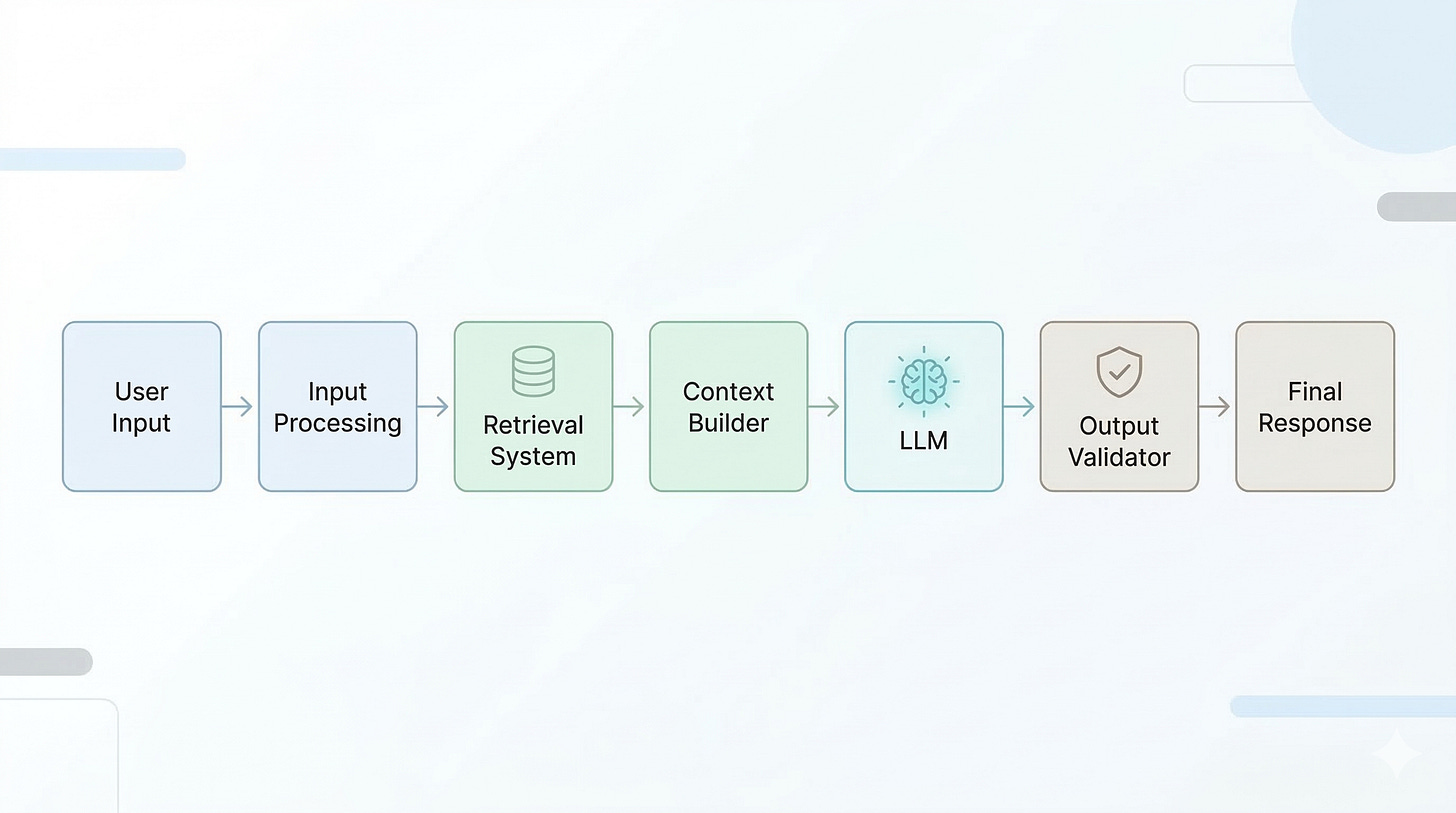
If you are building agents, the same idea holds. The “agent” is not the model. The agent is the loop that plans, calls tools, checks results, and decides when to stop.
If you are building RAG, the same idea holds. RAG is not “add a vector database.” It is a context supply chain with its own SLAs.
So, the mindset is not “how do I prompt better.” It is “how do I design the system so the model cannot easily do the wrong thing, and so I can see it when it does.”
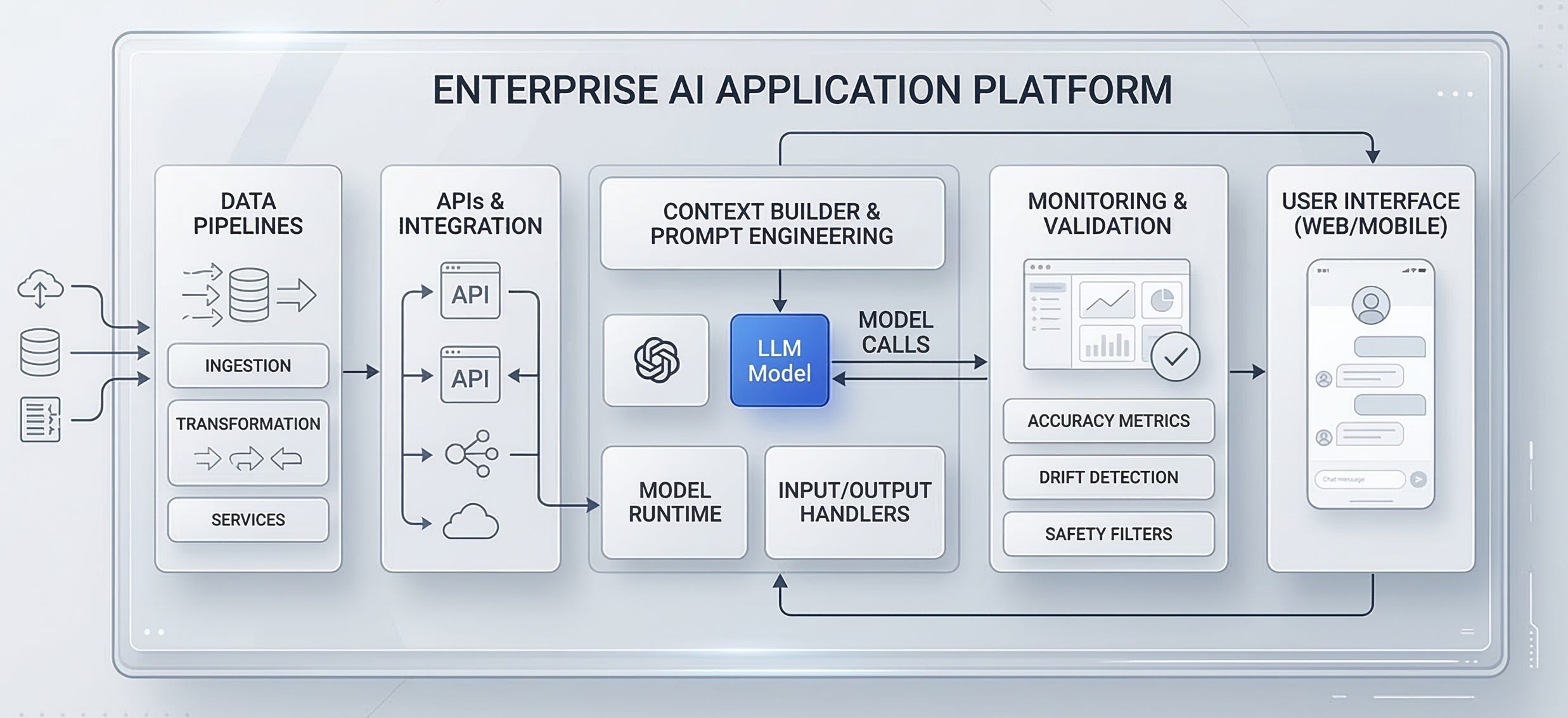
A reference architecture you can reason about
Understanding the architecture matters because it gives you levers you can actually pull when things go wrong.
A useful mental picture is to split the product into three planes:
Data plane: how knowledge and events enter the system.
Decision plane: how the system chooses what to do for a request.
Execution plane: how the system produces outputs and takes actions safely.
Here is a text diagram you can map to your own stack:
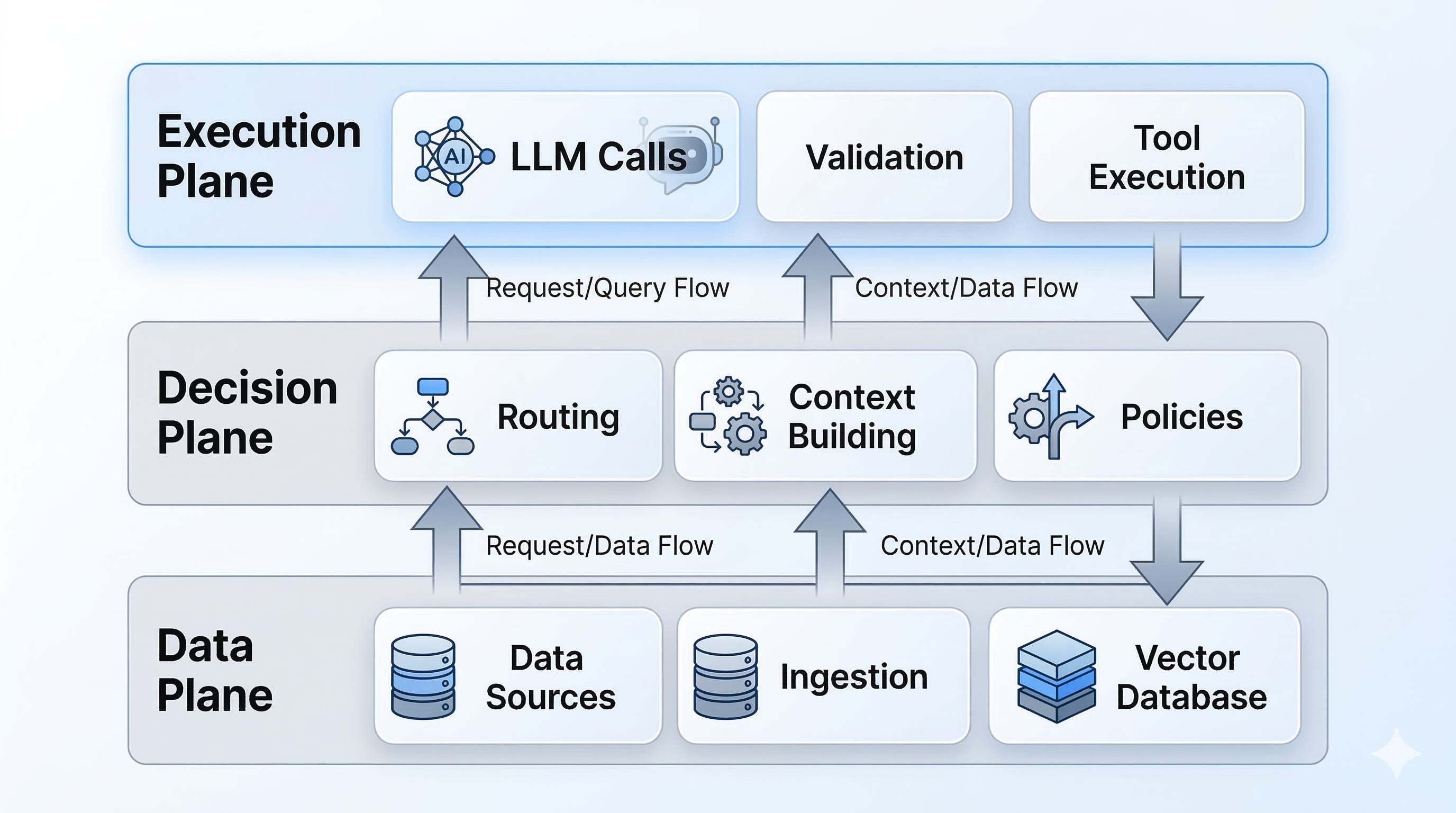
Data plane
Sources: docs, tickets, code, CRM, product DB, event streams
Ingestion: ETL, cleaning, chunking, metadata, access control tags
Indexes: vector index, keyword index, hybrid retrieval, caches
Evaluation data: golden sets, adversarial examples, regression suites
Decision plane
Request router: classify intent, pick workflow, pick model
Context builder: retrieve, rerank, filter by permissions, assemble context
Policy layer: safety rules, compliance constraints, tool allowlists
Budgeting: latency and token budgets, fallback thresholds
Execution plane
LLM call: prompt, tools, structured output schema
Validators: JSON schema, business rules, citation checks, PII redaction
Tool execution: idempotent calls, retries, timeouts, sandboxing
Response composer: user-facing answer, citations, next steps
Telemetry: traces, token counts, retrieval stats, outcome labels
This maps cleanly to patterns that show up in real deployments: a business microservice (often FastAPI) orchestrates retrieval and generation, while model serving sits behind a managed endpoint. In the “LLM Twin” style systems, you also see a full pipeline from data collection (LinkedIn, Medium, GitHub) into a store like MongoDB, then a feature pipeline that builds a vector index for RAG, then an inference service deployed behind an endpoint like SageMaker.
The point is not the specific tools. The point is separation of concerns. When the system fails, you want to know which plane failed and which lever fixes it.
How to build with the mindset, not against it
This section matters because most teams fail by building the happy path first and never building the control path.
Here is a build order that tends to work in practice.
Start with the contract, not the prompt
Why it matters: prompts are easy to change, but contracts define what “correct” means.
Define the output shape. Use structured outputs where possible.
Define allowed actions. Make tool calls explicit and typed.
Define refusal and escalation behavior. Decide what happens when context is missing.
Build the context supply chain as a product
Why it matters: most “model issues” are retrieval and context issues.
Ingestion: chunking strategy, metadata, and versioning.
Retrieval: hybrid search, filters, and reranking.
Permissions: enforce access control at retrieval time, not in the prompt.
Freshness: TTLs, reindex triggers, and cache invalidation.
Add guardrails that are software, not vibes
Why it matters: you cannot rely on the model to police itself.
Validate outputs with schemas and business rules.
Add citation requirements for factual claims.
Redact PII and secrets in both inputs and outputs.
Use allowlists for tools and domains.
Design for failure paths on day one
Why it matters: in production, the common case includes failures.
Timeouts and retries for tools.
Fallback models or fallback workflows.
“I do not know” behavior that is actually acceptable to users.
Human-in-the-loop queues for high-risk actions.
Instrument everything you will later argue about
Why it matters: without traces, you will debug by guessing.
Log retrieval queries, top-k docs, and reranker scores.
Trace token usage, latency, and tool call graphs.
Store prompts and responses with privacy controls.
Capture outcome labels. Even weak labels help.
Build evaluation like you build tests
Why it matters: open-ended outputs need regression protection.
Create a golden set from real traffic.
Add adversarial cases: empty context, conflicting docs, ambiguous requests.
Track task metrics and system metrics together.
Gate releases on eval deltas, not on “it seems fine.”
Close the loop with continuous testing and deployment
Why it matters: the system changes even when you do not deploy code.
Automate CI/CD and continuous testing for prompts, retrieval configs, and workflows.
Version indexes and prompts like code.
Roll out with canaries and fast rollback.
This is where the AI engineering workflow differs from older ML workflows. You can start with product iteration first, then invest in data and model adaptation once the product proves value. That iteration speed is a competitive advantage, but only if you also build the safety rails.
What building real systems teaches you
This section matters because the mindset is mostly learned by watching systems fail.
A few patterns show up consistently in real deployments.
First, most failures are upstream of the model.

Retrieval returns the wrong thing. Context is too long and the relevant part gets buried. The index is stale. Or the user’s permissions are not enforced. The model then does what it always does. It produces a plausible answer.
Second, latency and cost become product constraints fast. In most production systems, you end up with explicit budgets. You cap context size. You cache retrieval. You route simple requests to cheaper models. You move from “best possible answer” to “best answer within 800 ms and 2,000 tokens.”
Third, evaluation is the real moat. Not because it is glamorous, but because it is how you ship changes without fear. Teams that treat eval as a first-class artifact can iterate weekly. Teams that do not end up frozen, because every change risks a new class of hallucinations.
Fourth, agents fail in ways that look like competence. They will take actions based on partial evidence. They will chain tool calls that amplify an early mistake. If you do not build idempotency, tool timeouts, and step-level validation, you will eventually ship a system that is “usually right” and occasionally catastrophic.
Finally, the best product improvements often come from boring engineering. Better chunking. Better metadata. Better caching. Better routing. Better traces. These changes do not look like “AI breakthroughs,” but they move your reliability curve.
A decision framework you can use on every feature
This came from real systems, not theory.
When you add a new AI feature, run it through a simple framework: the COVE loop.
COVE stands for Contract, Observability, Verification, and Economics.
Contract
Define what the system must do, and what it must never do.
What is the output format?
What actions are allowed?
What is the acceptable error mode?
What is the escalation path?
If you cannot write this down, you are still in demo mode.
Observability
Decide what you need to see to debug and improve.
Can you trace a request end-to-end?
Can you inspect retrieval results and context?
Can you reproduce an output deterministically enough to investigate?
Do you have outcome labels, even if they are noisy?
If you cannot see it, you cannot improve it.
Verification
Add checks that catch failures before users do.
Schema validation and business rule checks
Citation and grounding checks for factual tasks
Tool call constraints and idempotency
Offline eval suites and regression gates
If you cannot verify it, you are relying on luck.
Economics
Make the feature viable under real usage.
Latency budgets per step
Token budgets and context limits
Model routing and caching strategy
Cost per successful outcome, not cost per call
If you cannot afford it, you cannot scale it.
You can apply COVE at design time and again during incident reviews. It also maps cleanly to the three-plane architecture. Contract and verification live in the decision and execution planes. Observability spans all planes. Economics forces tradeoffs across the whole system.
What to take from this
The model is not the product, the system is.
Most reliability work is context, constraints, and evaluation, not clever prompting.
If you cannot observe and verify behavior, you cannot ship changes safely.
The difference between an AI demo and an AI product is not the model. It is the contract you build around uncertainty.