
When to Fine-Tune vs When to RAG: A Data-and-Eval Checklist (with Break-Even Math)
The fastest way to waste a month is to fine-tune for a retrieval problem
If your agent is giving wrong answers, your first instinct is often to fine-tune.
Then you discover the “wrong” answers were correct last week, but your policy doc changed yesterday, your product catalog updated this morning, and your incident runbook got rewritten after the last outage.
The reason your agent fails is not model capability. It is data freshness.
Choosing fine-tuning vs RAG is an evaluation decision first, and an architecture decision second.
Fine-tuning and RAG solve different failure modes
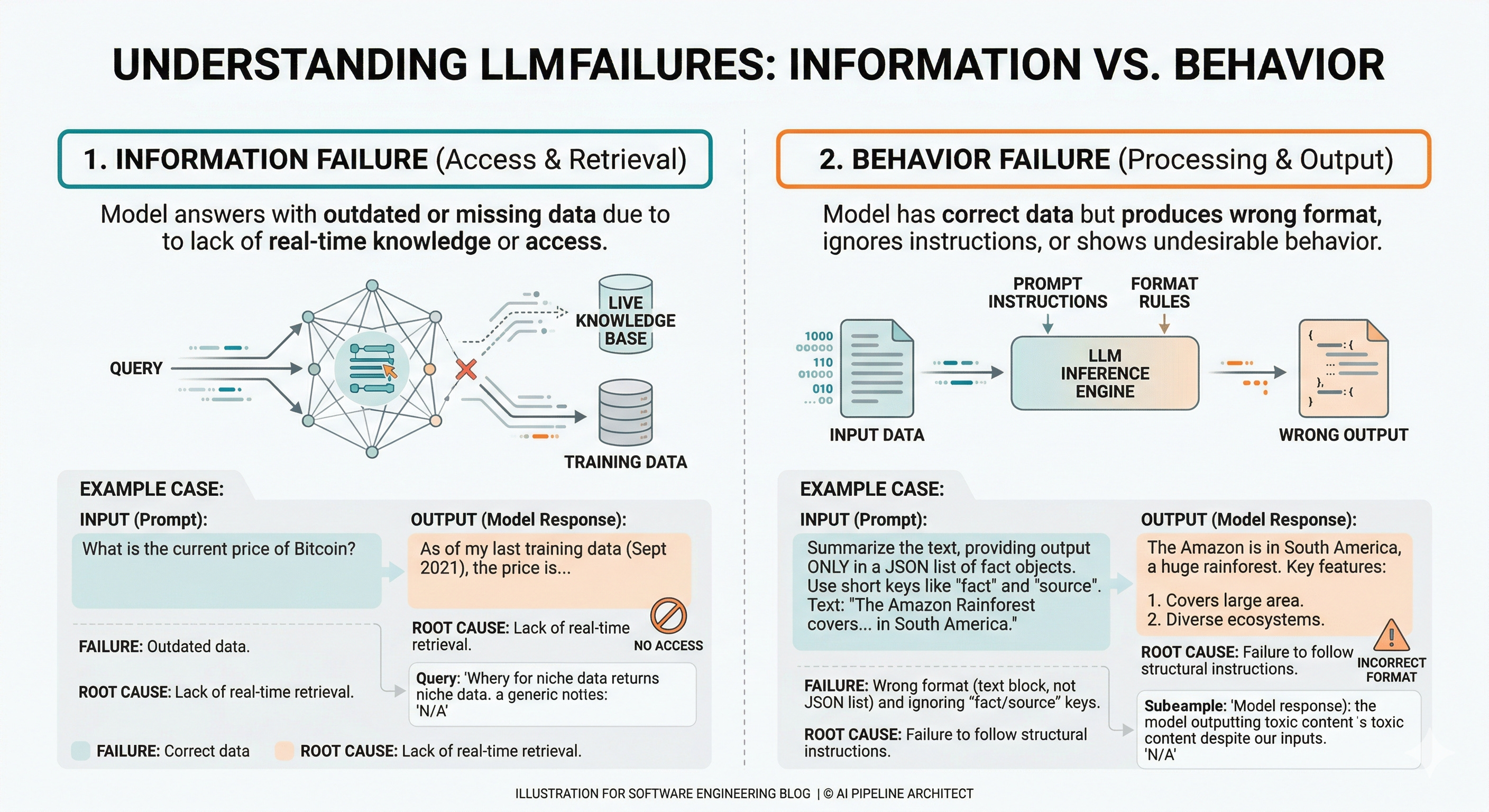
Start with a blunt classification: most agent failures are either information failures or behavior failures.
Information failures mean the model cannot access the right facts at the moment it answers. The output is outdated, missing private details, or confidently wrong because the model is guessing.
Behavior failures mean the model has the facts but does the wrong thing with them. It ignores instructions, produces the wrong format, misses required fields, or writes something that is technically true but unusable for the task.
RAG (Retrieval-Augmented Generation, a pattern where the model looks up relevant documents before answering) primarily fixes information failures by grounding the answer in your current sources of truth.
Fine-tuning (updating a model’s weights using examples) primarily fixes behavior failures by shaping how the model responds even when the prompt is imperfect.
This split shows up in published results. For tasks that require up-to-date information, RAG can outperform fine-tuning, and in at least one study RAG on the base model beat RAG on fine-tuned models for current events QA.
Fine-tuning can also reduce performance in other areas, because you are pushing the model toward a narrower behavior distribution.
A useful operational translation:
If the agent is wrong, ask: was it wrong because it did not know, or because it did not comply?
The system you are actually building
Understanding the structure matters because fine-tuning and RAG move complexity to different parts of the system.
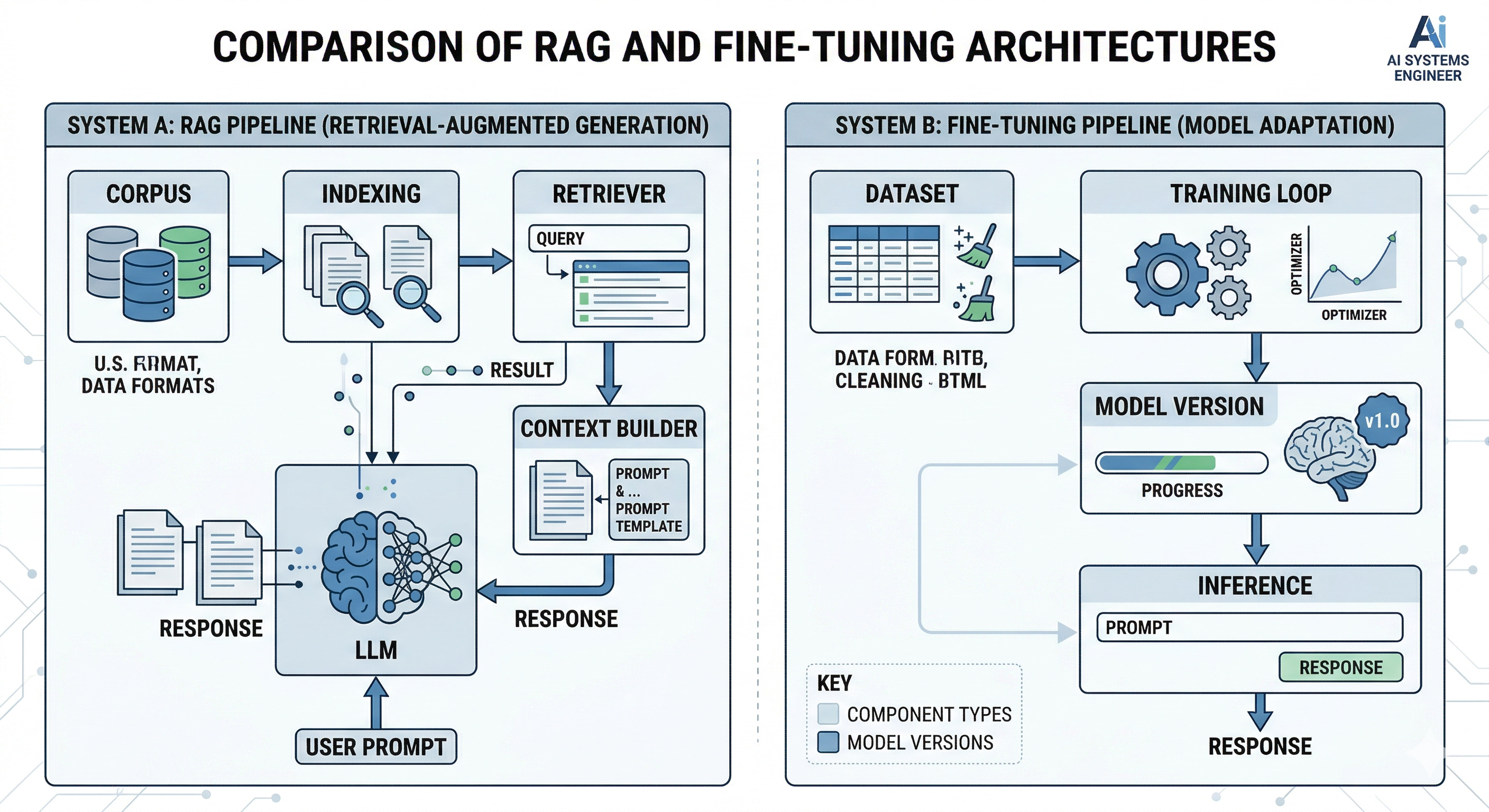
A production agent is not “a model.” It is a pipeline with failure points.
RAG adds components at inference time:
A corpus (your docs, tickets, runbooks, product data)
An indexing pipeline (cleaning, chunking, embedding)
A retriever (search that returns candidate passages)
A context builder (how you pack retrieved text into the prompt)
A generator (the LLM call)
Monitoring (to catch drift, latency spikes, and retrieval failures)
Fine-tuning adds components in development time:
A dataset (instruction examples and labels)
A training loop (often parameter-efficient methods like LoRA, Low-Rank Adaptation, which updates a small set of parameters)
A model registry and versioning (so you can roll back)
An evaluation harness (to prevent regressions)
The trade is simple:
RAG increases inference complexity. Fine-tuning increases model development complexity.
Agents amplify this trade because they call the model multiple times per user request. A single extra retrieval step can multiply into a latency and reliability problem when the agent loops, retries, or fans out across tools.
Here is the line most teams learn late:
If your agent needs to be correct about today, you are building a data system, not a model system.
Build the eval first, then the checklist decides the architecture
Implementation starts with an evaluation harness because otherwise you will “feel” improvements that do not survive contact with production.
You need a small, high-signal dataset that reflects agent reality: multi-turn, tool calls, and the kinds of questions users actually ask.
Create an error taxonomy that matches the decision
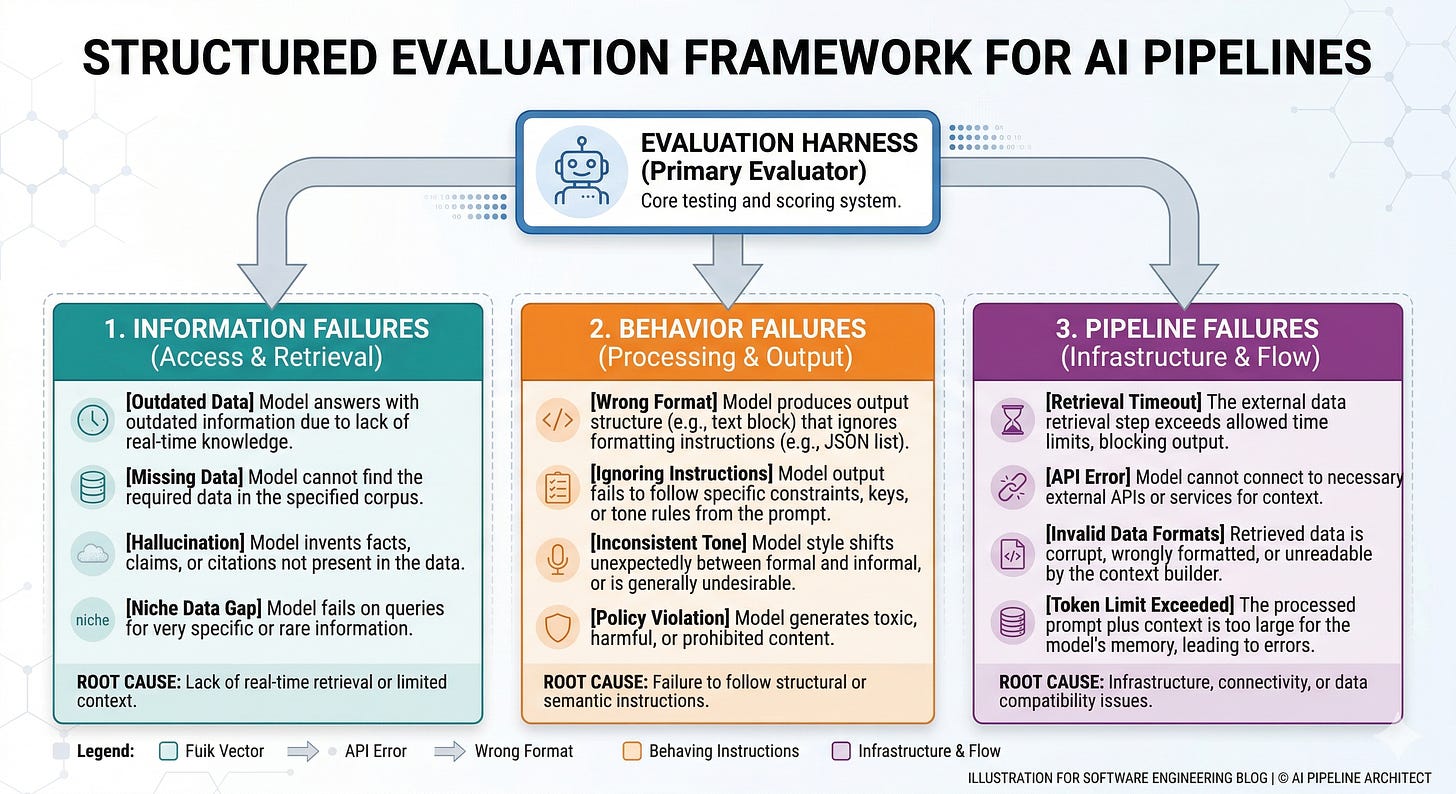
Label each failure as information-based or behavior-based.
Add a third bucket for pipeline failures: retrieval timeout, empty results, tool error, or context overflow (when the prompt gets too long and important text is dropped).
If you skip the pipeline bucket, you will blame the model for what is actually a systems issue.
Add a freshness field to every example
For each question, record whether the answer changes with time.
Examples: “current on-call rotation,” “latest pricing,” “today’s incident status,” “most recent policy.”
Freshness is not a nice-to-have metric in RAG. It is the whole point.
Define success metrics that separate retrieval from generation
Retrieval accuracy: did you fetch the right documents?
Faithfulness: did the answer stay grounded in retrieved text, or invent?
Task success: did the agent produce the required output or take the correct action?
Tooling exists for this. Ragas (a toolkit for RAG evaluation) and ARES (an automated evaluation framework that uses synthetic data plus classifiers) are both designed to score retrieval relevance and answer faithfulness, then monitor those signals in production.
Run two baselines before you touch training
Prompt-only baseline with a versioned prompt.
Simple retrieval baseline, starting with term-based search (keyword search) before embedding-based retrieval (search by meaning using vector embeddings).
Simple retrieval often buys you more than you expect, and it is easier to debug than semantic retrieval.
Add slicing so you do not get fooled by averages
Slice by question type: policy, troubleshooting, product, compliance.
Slice by input length and required format.
Slice by “freshness required” vs “static knowledge.”
Slice-based evaluation prevents Simpson’s paradox, where the aggregate looks better while every important slice gets worse.
Break-even math you can actually use
In practice, the decision becomes economic once you have the eval results.
You are comparing two cost curves: per-query retrieval cost vs amortized training cost.
Define:
N = number of queries over the model version lifetime
C_r = incremental cost per query for RAG (retrieval compute, extra tokens for context, added latency cost)
C_ft = one-time fine-tuning cost (training compute, data labeling, evaluation, deployment)
C_m = ongoing maintenance cost per version (monitoring, regressions, periodic refresh)
ΔQ = quality gain you need (measured in your eval metric, not vibes)
A simple break-even for cost is:
Fine-tuning is cheaper when C_ft + C_m < N * C_r
Solve for N:
N_break-even = (C_ft + C_m) / C_r
This is not theoretical. It forces you to quantify what you are paying for.
Now add the constraint most teams miss:
If the knowledge changes faster than your fine-tune cycle, the effective quality gain from fine-tuning on knowledge is negative.
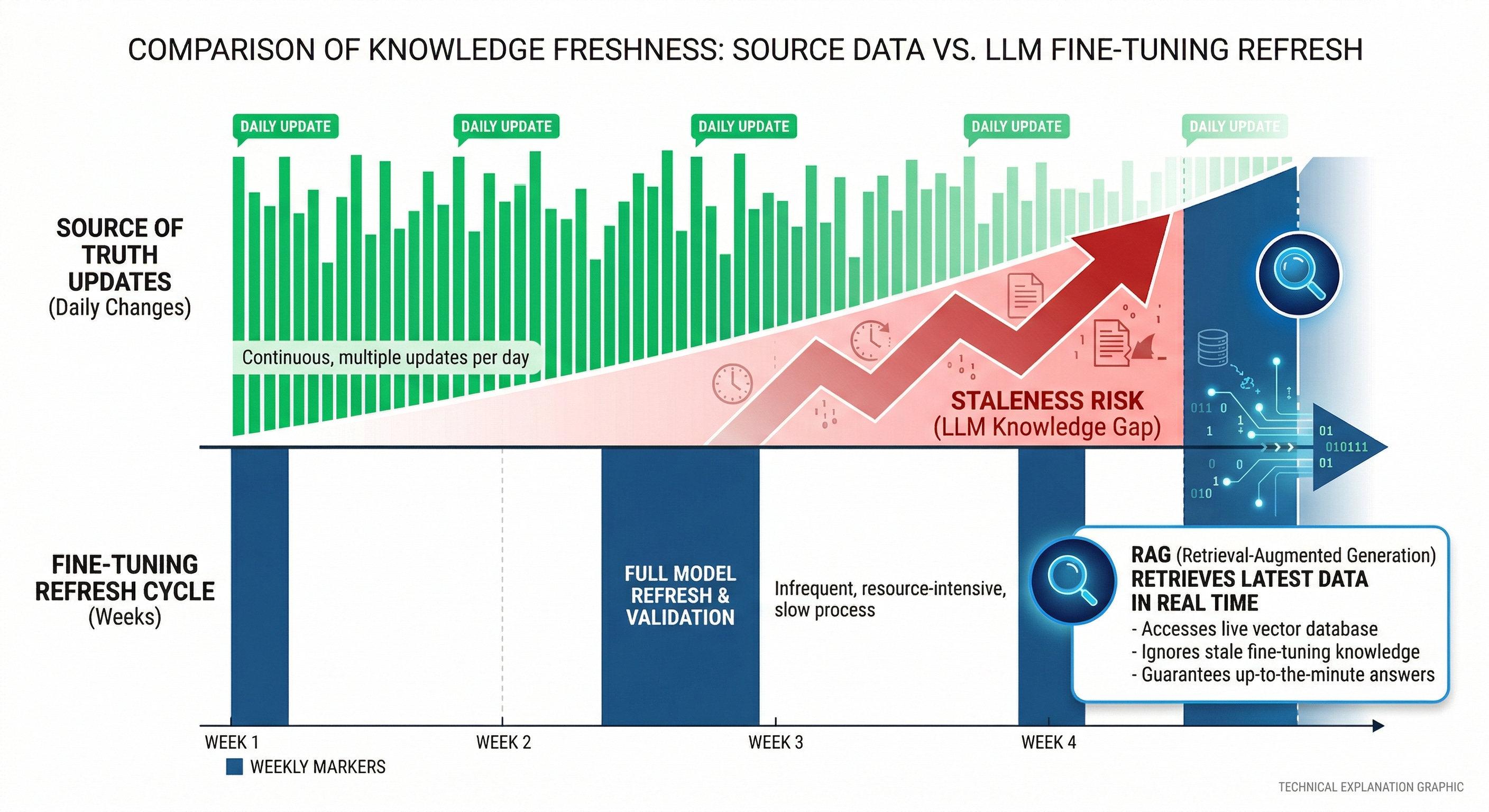
You can model that as a staleness penalty:
T_update = how often the source of truth changes
T_refresh = how often you can realistically fine-tune and redeploy
P_stale = probability a query hits changed knowledge between refreshes
If T_refresh >> T_update, P_stale approaches 1 for freshness-sensitive queries.
That pushes you toward RAG even if fine-tuning “breaks even” on cost, because the system will be wrong by construction.
A practical way to implement this in your checklist:
Estimate C_r by measuring the delta between prompt-only and RAG runs
Added tokens for retrieved context
Added latency from retrieval and reranking (if any)
Added failure rate from extra dependencies
Estimate C_ft + C_m using your actual workflow
Data labeling time
Training runs and iteration
Evaluation and regression testing
Deployment and rollback overhead
Compute N_break-even for each agent capability
“Answer policy questions” might have a different N than “generate structured tickets.”
Apply the freshness constraint as a hard gate
If the capability depends on frequently changing knowledge, fine-tuning cannot be the primary mechanism.
One screenshottable rule that holds up:
If you cannot keep the weights fresh, do not put knowledge in the weights.
What tends to happen in production
In most real-world cases, teams fine-tune too early because they are trying to fix a pipeline problem with a model change.
RAG systems fail in predictable ways:
Stale indexes: your documents updated, but your embedding pipeline did not rerun, so retrieval returns yesterday’s truth.
Synchronization gaps: the source of truth changed, but the retrieval corpus lags by hours.
“Right doc, wrong snippet”: retrieval finds the correct document, but chunking (splitting documents into passages) cut the key sentence away from its context.
Latency cliffs: the agent works in dev, then falls over when concurrent users trigger slow queries.
Fine-tuning fails in different ways:
You fix formatting but lose generality, and the model becomes brittle outside the training distribution.
You bake in policies that change, then spend your life chasing retrains.
You improve one slice and silently regress another because you did not slice your eval.
The operational lesson is not “RAG good, fine-tuning bad.”
The lesson is that each approach has a dominant failure mode, and you should choose the failure mode you can tolerate.
Another screenshottable line:
RAG failures look like data engineering. Fine-tuning failures look like product debt.
A decision framework that survives contact with agents
This framework comes from the pattern that shows up when you debug agents under load: separate what must be retrieved from what must be learned.
Put changing knowledge behind retrieval
Policies, runbooks, catalogs, pricing, incident status.
Anything with an owner who edits it weekly.
Put stable behavior into fine-tuning
Output schemas and formatting.
Tool-use style, like how to write a ticket, how to summarize an incident, how to ask clarifying questions.
Domain tone and relevance, when the model is correct but not useful.
Use evaluation slices to decide hybrids
If RAG fixes freshness slices but the agent still fails formatting slices, fine-tune for behavior on top of RAG.
Expect diminishing returns. In one reported experiment, adding RAG on top of a fine-tuned model improved performance less than half the time compared to RAG alone.
Treat freshness as a first-class SLO
An SLO (service level objective, a reliability target) for RAG is not just latency and accuracy.
It is also “time to reflect source-of-truth changes in answers.”
If you cannot measure freshness, you cannot claim correctness.
The three insights that change the build
Your first job is to classify failures into information, behavior, and pipeline.
Freshness is a gating constraint, not an optimization target.
Break-even math only matters after evaluation tells you which failure mode you are paying to fix.
Fine-tuning vs RAG is not a model choice, but a systems choice.
Which capability in your agent is currently failing because it cannot access today’s truth, and which is failing because it cannot reliably execute a stable behavior?